



Language models (LMs) are statistical compressions of the data they're trained on.
They're trained to predict the next token in a sequence picking up a bunch of other skills along the way.
So a model trained on a whole lot of the internet will learn about wikipedia and blogposts and fanfiction and all sorts of other text. When you sample text from them, you'll be able to generate large swaths of information that could come from any of those sources. But it's kind of tough to get what you want out of it, or even just to get what you ask for.
After all, how many reddit comments are useful compared to the number of responses? How many open-source code repositories are up to date, and high-quality? And when you ask, "write a funny tweet", you probably don't want the continuation "about machine learning" - you want a tweet!
So we want our language models to be something more task specific. And that task could be anything! It could be a helpful assistant, like ChatGPT, or it could be a code reviewer, a language coach, text summarizer, or videogame player.
How do we transform a general language model to this? Well we need to fine tune them for our desired response! We could use prompting to get something, since LMs are so general, but prompting can be tedious, limited to what fits in context and may not generalize well. Fine tuning allows us to repeatedly, and reliably, access a certain 'persona' out of the LM.
And even how it does any (or all) of these things can be changed. It all depends on your preferences.
Today, we're going to train and finetune GPT-2 from scratch on different preferences - first we'll train a small model to generate positive tweets, then we'll implement the text summarization described in the Learning to Summarize from Human Feedback paper, touching on all the components along the way.
So, what is RLHF?
Briefly, RLHF is the secret sauce that makes ChatGPT answer your questions.
RLHF, or reinforcement learning from human feedback, is one method of this finetuning. It uses reinforcement learning to update the language based on a task that we want it to perform.
There are 4 main parts to the RLHF setup:
1. The task
Reinforcement learning operates over a task, or "environment". A task is just the particular thing that you want your model to get good at. Or, to be a little more technical, an environment is a state machine that accepts an agent’s actions and transitions to a subsequent state emitting a reward in the process.
2. The language model
The language model is the brain here. It is the agent carrying out the task. It's going to generate our outputs for us to rate or rank and improve via RLHF. We'll start with the simple gpt-2 models from Andrej Karpathy's minGPT repo and extend it to include preference finetuning.
3. The reward function
In order to improve, we need a metric to measure progress. Some tasks may be easy to measure, like winning in chess, whereas others, like human preferences, are broad and hard to specify, but can be approximately learnt from a dataset. We use scores from our reward function to guide our LM to produce better responses using a learning algorithm.
4. The learning algorithm
There are plenty of options for learning algorithms here, and not just RL ones. But RL supports arbitrary black-box, non-differentiable rewards, and OpenAI used it in their InstructGPT paper too. It's not RLHF for nothing!
>discussing RLHF implementation
>is the algorithm OpenAI or DeepMind?
>explain scaling
>explain jax updates, deep MCTS, popart normalization
>”its a good algorithm sir”
>its PPOHappyGPT from scratch
First, we are going to train a mini GPT-2 model (0.8M parameters) on tweets and we're going to finetune the lil guy to be as positive as possible. I call him HappyGPT. He's kind of simple, but he's content with that. And we get to see an end to end training process in only a few minutes!
Who knew RL was this easy!
A brief recap of GPT
If you haven't already watched Andrej Karpathy's youtube intro to building language models, you're seriously missing out. Not only because transformers are the most capable piece of AI that we've ever invented
Our decoder-only transformer is pretty straight-forward and uses the same multi-head attention blocks from minGPT. For future convenience, we pull out the transformer decoder blocks into a torch module, and we optionally pass through an attention mask in the forward function. We can use the attention mask to prevent the transformer from attending to any padding tokens in the input, combining it with the causal mask which only attends to tokens from the past.
HappyGPT is a small 0.8 million parameter model. Miniscule in the day and age of billion parameter models, but trainable locally in only a few minutes, even on CPU!
class Transformer(nn.Module):
def __init__(self, config):
super().__init__()
self.block_size = config.block_size
self.wte = nn.Embedding(config.vocab_size, config.n_embd)
self.wpe = nn.Embedding(config.block_size, config.n_embd)
self.embd_drop = nn.Dropout(config.embd_pdrop)
self.blocks = nn.ModuleList([Block(config) for _ in range(config.n_layer)])
self.norm = nn.LayerNorm(config.n_embd)
def forward(self, idx, attention_mask=None):
b, t = idx.size()
assert t <= self.block_size, f"Cannot forward sequence of length {t}, block size is only {self.block_size}"
pos = torch.arange(0, t, dtype=torch.long, device=idx.device).unsqueeze(0) # shape (1, t)
tok_emb = self.wte(idx) # token embeddings of shape (b, t, n_embd)
pos_emb = self.wpe(pos) # position embeddings of shape (1, t, n_embd)
x = self.embd_drop(tok_emb + pos_emb)
for block in self.blocks:
x = block(x, attention_mask=attention_mask)
return self.norm(x)First we will pretrain our LM on this dataset of tweets. There are a total of 27k tweets which we learn on. We use a simple character level tokenizer for this task, the same as in minGPT. Here are a few dataset examples:
| Tweet | Sentiment |
|---|---|
| He`s awesome... Have you worked with him before? He`s a good friend. | positive |
| i lost all my friends, i`m alone and sleepy..i wanna go home | negative |
| If you know such agent, do let me know | neutral |
After 5000 iterations we get down to about 1.6 loss and can approximate some tweets. Not bad for 0.8M parameters!.
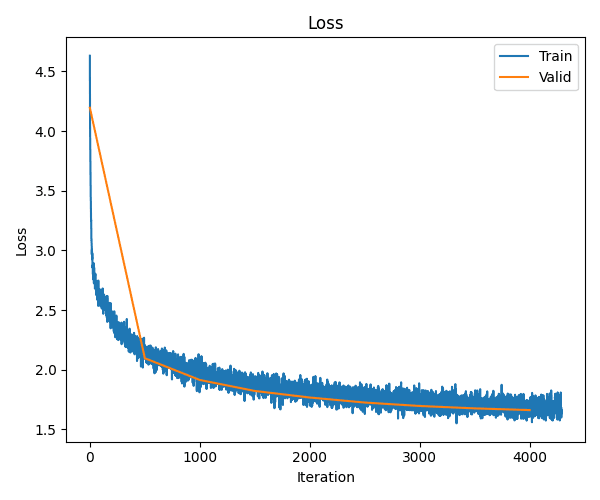
Let's look at a few random generations. For such a small character-level model, we can start to pick out words! But they're not particularly happy yet!
> I think I wish i could see your my hair comments!!
> going my friends taine main tex
> Seems rub to be hanging out.... will!Supervised finetuning is quite simply a bit more pretraining, but on a curated dataset. So, for happyGPT, we train on the 'positive' labeled tweets from the same dataset - pretty simple!
> I think I`m over glad it`s nite time
> I`m leappy mothers day
> good to somedmae to takes me with the picky finalOur lil friend is learning!!
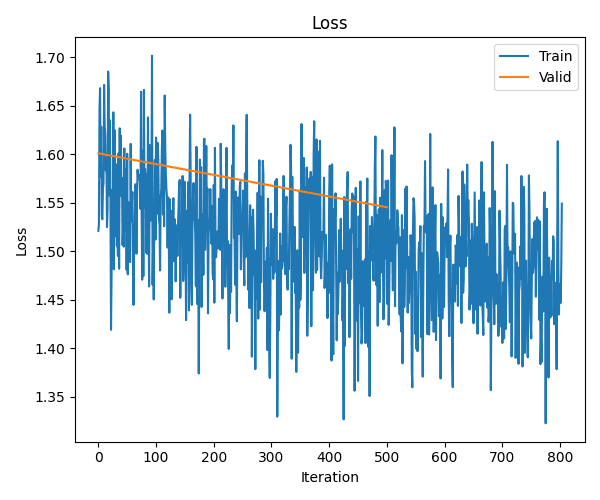
Sentiment reward function
The reward function is a score for our model's generated completion and a rating for how well the model did on our task. For happyGPT, we will use a heuristic sentiment analysis score from nltk, a library of natural language functions.
In particular, we'll use the SentimentIntensityAnalyzer which uses a set of rules to estimate a sentiment score for a sentence. It's pretty decent actually! You simply pass in a sentence and it provides a sentiment score between -1 and 1.
sid = SentimentIntensityAnalyzer()
scores = sid.polarity_scores(sentence)
# The movie was too good
# compound: 0.4404, negative: 0.0, neutral: 0.58, positive: 0.42
# This movie was actually neither that funny, nor super witty.
# compound: -0.6759, negative: 0.41, neutral: 0.59, positive: 0.0The learning algorithm
The policy gradient is pretty simple. We are trying to maximize the expected reward of our LM from our reward function.
So we apply the chain rule, bippity boppity
Simple right? We just need the log probs from our LM, and the rewards from our reward model, and we can optimize it! Now put that into pytorch, and we can finetune our language model!
The core of RLHF
These 10 lines of code make up the core of RLHF! We sample completions from our LM given some prompt. Then we score them using the reward model, and use those completions and rewards to optimize our model towards the better performing completions.
with torch.no_grad():
# Sample new tweets
model.eval()
completion = model.generate(prompt, max_new_tokens=block_size, temperature=1.0, do_sample=True, top_k=30)
model.train()
# Evaluate the rewards
rewards = reward_model(completion)
# Get the LM log probs
log_probs = model.log_probs(completion, target)
# Calculate the vanilla policy gradient loss
pg_loss = -torch.mean(rewards * log_probs)
# Optimize the model
pg_loss.backward()
optimizer.step()
model.zero_grad(set_to_none=True)Do this a few times, and we can learn to maximize the reward:
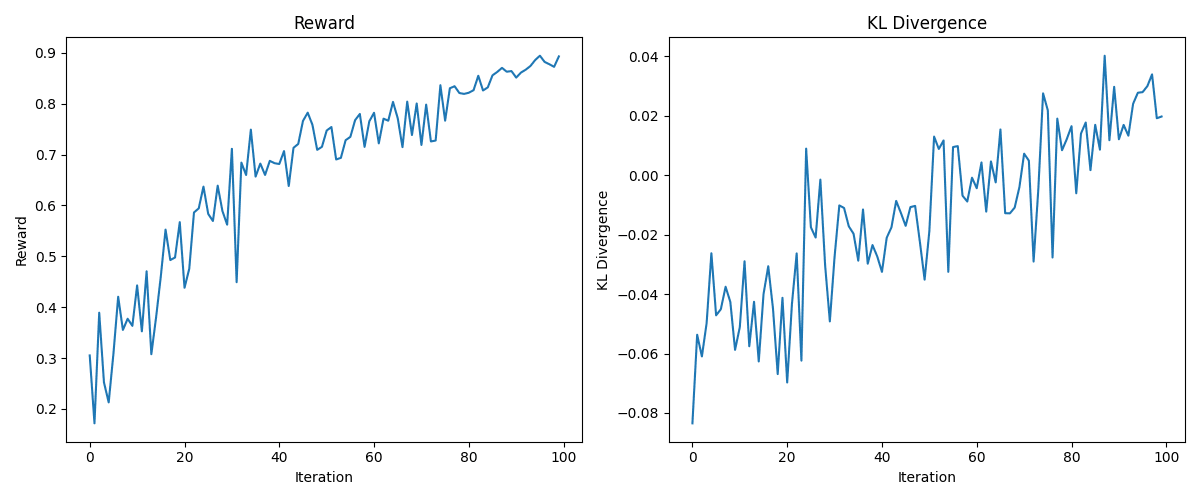
Look at that sweet, sweet reward! Here are some random generations.
I hope yes yeah! Hi hAHA. I lovely!!!!
Like the luckyyy! Things today, almost!
Last? LOVe in the SAves haha
I love guy twitte! I`ve with a good
HAPPY MOTHER`S Day!!!!!!!Our little HappyGPT is all grown up. Fully RLHF'ed and all! Aren't you proud!
InstructGPT text summarization
Now we're off to the big leagues. Time to train a Serious™ InstructGPT-type model on a Serious™ task. We'll use one of the earliest preference finetuning tasks, reddit post summarization, initialized from the pretrained 124M parameter GPT-2 model.
Again, we begin by finetuning on the preferred responses from the summarization dataset. Right off the bat we get a something much better than baseline!
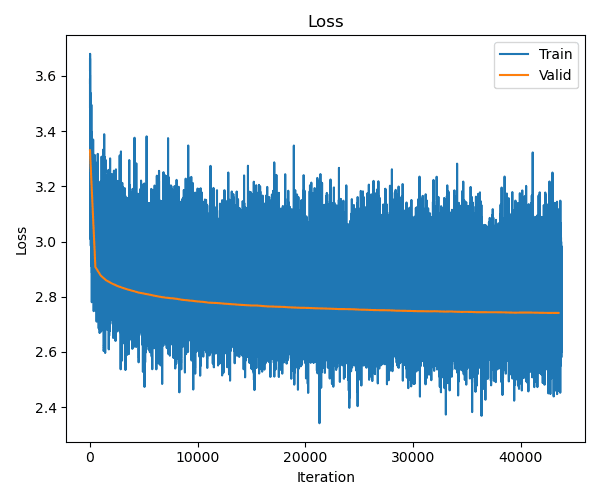
You can see it give a decent effort at summarizing a post on r/MachineLearning from a few days ago - quite far out of distribution compared to the relationship-type posts that it's seen more of. This is an excerpt of the post, but it goes on quite a bit more:
TITLE: [D] Is anyone else absolutely besieged by papers and always on the verge of getting scooped? POST: I'm a 1st year PhD student working on a hot area in ML (3 guesses as to what lol) and the past year has been absolutely brutal for me on a personal level. Every single weekday, I check the daily arxiv digest...
And our SFT generated summary:
TL;DR: I'm a 1st year PhD student working on a hot area in ML, and I'm worried that I'm being overwhelmed by papers and papers that I've already worked on.
Pairwise reward modelling
Next, we'll learn our own reward model using pairwise responses of better or worse summaries. Our reward model simply learns to minimize the loss: -log(sigmoid(better_response - worse_response)).
In other words, it's trying to rate the better responses higher than the worse responses. This particular form can support multiple responses, for each prompt - multiple people can write summaries and we can learn from all of them. No specific values are used in the optimization since different raters can disagree on an exact score for each review, but usually agree on the ranking of each.
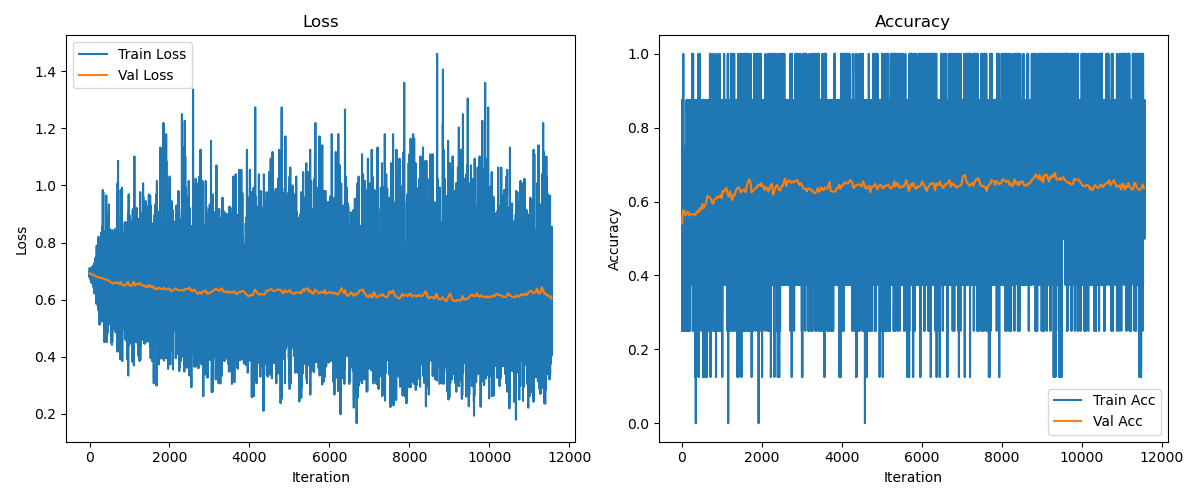
It's fairly difficult ranking similar summaries, so we only improve a bit, getting an accuracy at picking the better summary of about 65%. Nevertheless, the reward model does a decent job at identifying the more obviously good and bad responses!
Improved policy optimization
We'll also add some additional improvements to our RL optimization loop.
First, we'll learn a value function, which will estimate how good our LM is on a particular prompt. If the sample we generated is better than expected, we can optimize that response more. This is a trick to reduce the variance of our policy optimization, which should help with learning stability.
There are also other policy gradient algorithms that improve on this, one being "PPO", which OpenAI uses in InstructGPT. Additionally, in InstructGPT, they further extend the optimization to include a KL loss term to keep the LM close to the original SFT model to prevent overfitting to the reward function, or 'reward hacking'.
The PPO loss clips the reward advantage (how much better the summary is than average) so that it doesn't update the network too much. Have a look at spinning up for more of the details.
# Clipped PPO loss
logratio = log_probs - original_log_probs
ppo_ratio = logratio.exp()
pg_loss1 = -advantages * ppo_ratio
pg_loss2 = -advantages * torch.clamp(ppo_ratio, 0.8, 1.2)
pg_loss = torch.max(pg_loss1, pg_loss2).mean()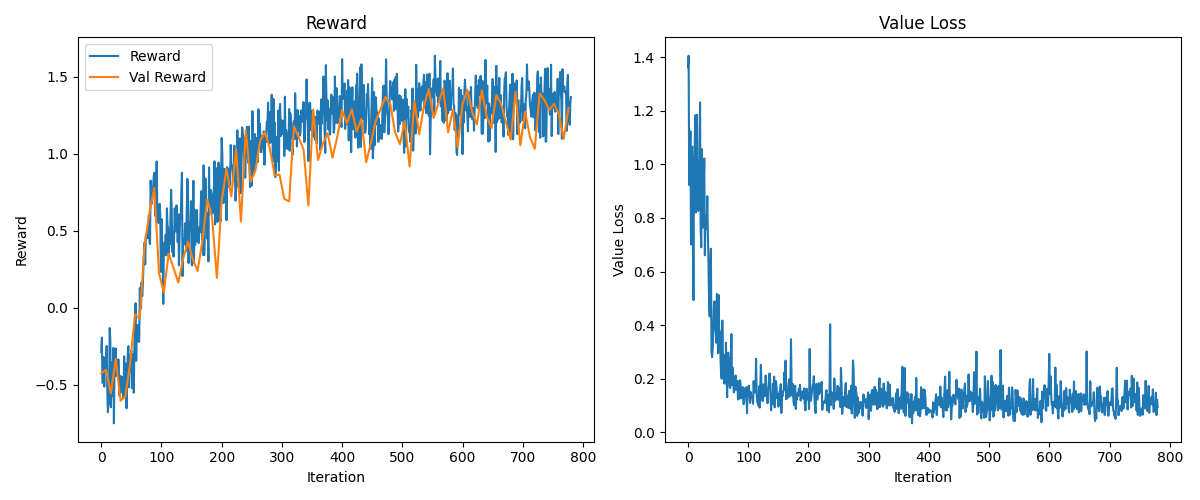
And the machine learning summary becomes:
TL;DR: Fast publication cycle from idea generation to execution to publication drives up anxiety, since I feel that speed is really the best comparative advantage here; it's all speed iteration from idea generation to Execution to publication. Is anyone else in the same boat? Does anyone have helpful advice...for dealing with the stress of fast publication cycles
We can even summarize other things, like the abstract of the GPT-3 paper:
Language Models are Few-shot Learners: scaling up language models greatly improves task-agnostic, language models that humans can generally perform a new language task from only some examples or from simple instructions – something which current NLP systems still largelystruggle to do.
So what next?
Next time we'll try to compete on tasks that are more up to date with bigger and better models!
If you have any thoughts or questions, feel free to tweet me @tomtumiel.
And you can find the minRLHF repo here: https://github.com/ttumiel/minrlhf
And, in the wise words of a drastically overfit HappyGPT:
love love love love love love
Acknowledgements
I'd like to thank Charlotte Allard for her help writing this blogpost.
Extra Notes & Thoughts
Here are a few extra thoughts that I had whilst writing the blogpost and implementing the code that didn't quite fit in the main piece. It's more raw and unrefined, so take them with a grain of salt.
- The reward model is actually quite hard to optimize! Given 100000 summary comparisons, and a “straightforward” supervised objective, I had thought that the reward would perform better on validation.
- I think there is a lot of untrodden ground in the reward models. Inverse RL (learning the task, and thus reward model) was one of the more difficult sides of RL. Especially given sub-optimal data. Other interesting things can happen when choosing a different objective to optimize.
- The reference and reward models are frozen in RL - you could quantize to int8 (or smaller!) for faster inference in the RLHF. Additionally, the “generation” phase of RLHF takes more time (and memory) than the actual optimization - but PPO is meant to handle off-policy data - perhaps you can even quantize the generation every few iters for more speed.
- SFT is really simple and works really well. I was surprised by the SFT-only model generalizing to new, out-of-distribution examples (especially at the 124M parameter scale!!) Here the SFT model summarizes the GPT-3 paper abstract:
- I was surprised that the vanilla policy gradient was able to learn at all! For something so simple, it performed pretty much the same as the more complicated PPO implementation on HappyGPT.
- Our reward function is actually fully differentiable since it’s just a neural net, so why bother with all the pain of the policy gradient? My guess is that the reward is too easy to game to make the gradients useful, but I’d be interested in seeing more.